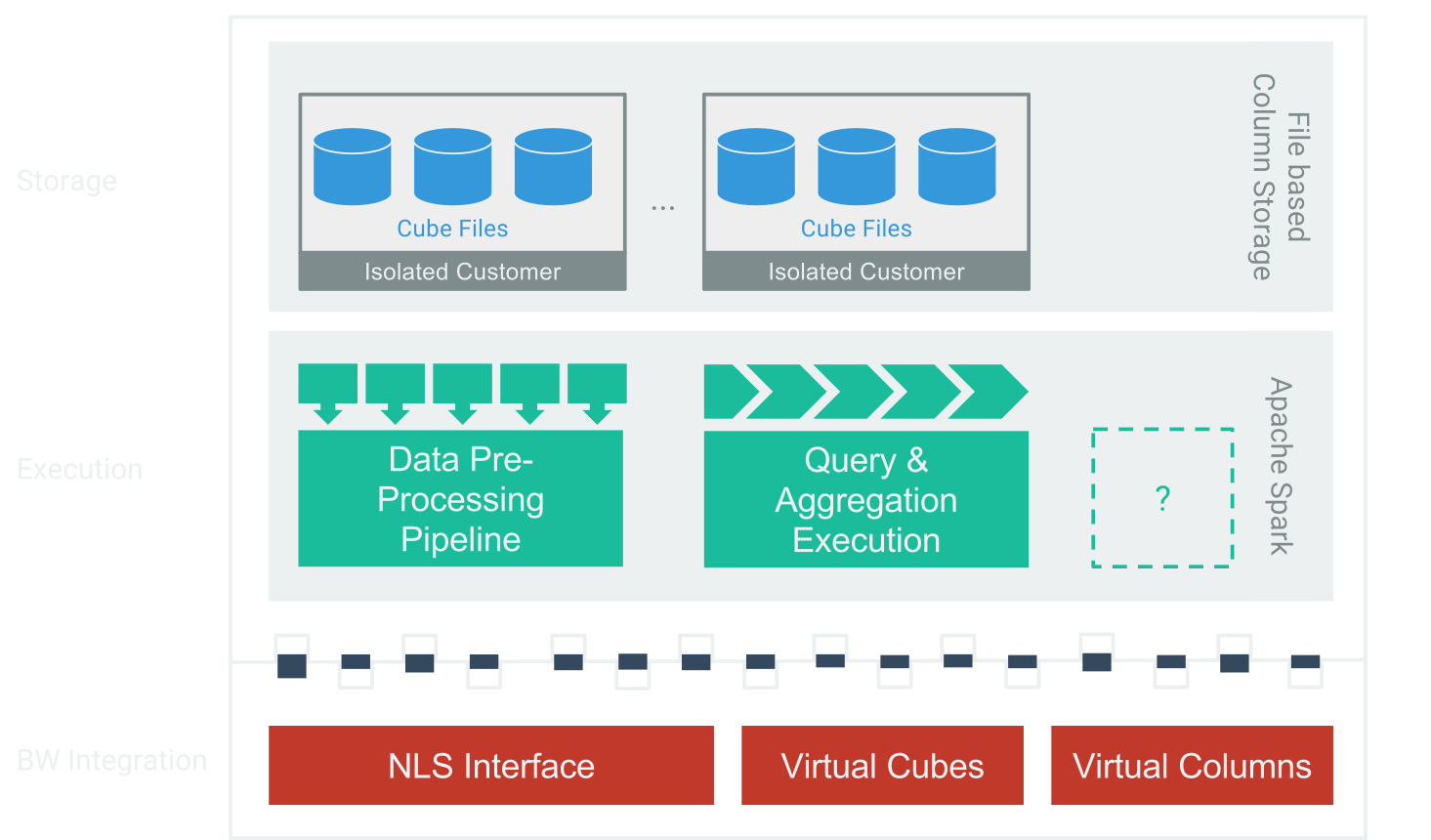
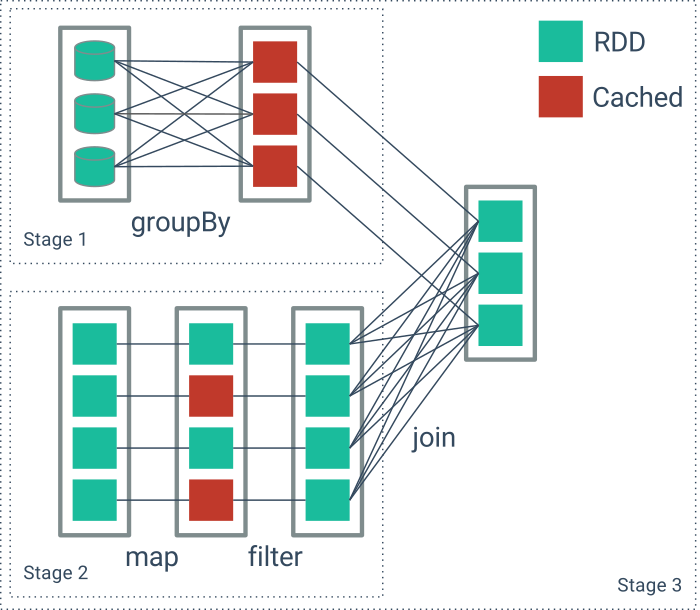
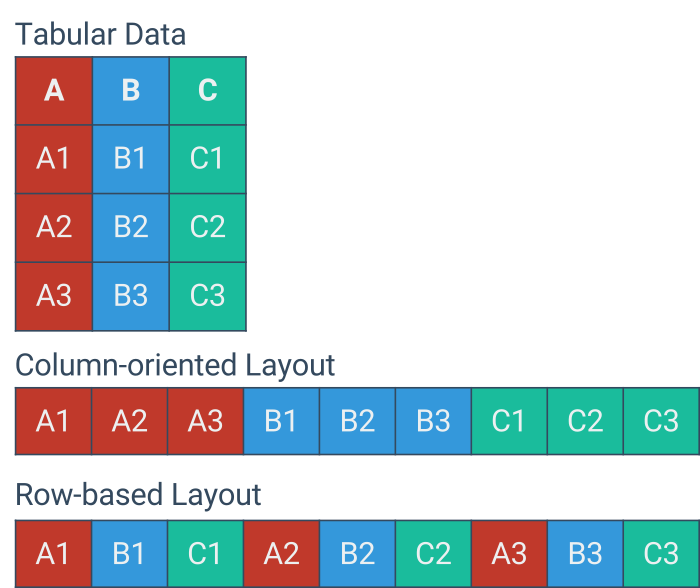
SparrowBI bietet In-Memory Performance zum Preis einer Archivierungslösung. Eine tiefe Integration in SAP-BW auf Basis von Standardschnittstellen erfordert keine Umstellung oder Einführung neuer Technologien. Die Ausführungs-Schicht basiert auf moderner, massiv paralleler In-Memory Technologie auf Basis von Apache Spark. Durch gehosteten Betrieb skaliert SparrowBI nach Bedarf. Zur Speicherung setzt SparrowBI auf Datei-basierte Spalten-Datenbanken die in einer performanten und redundaten IO-Architektur vorgehalten werden. Dabei bietet SparrowBI Daten-Sicherheit und Governance um Unternehmensdaten sicher vorzuhalten und auszuwerten.