Upload und Reporting von Daten
Eine flexible Sache!
Bei der ausschließlichen Nutzung von SparrowBI als Nearline-Storage werden die archivierten Daten eines Info-Providers bei einer Query auf diesen Info-Provider unverändert zurückgegeben.
In manchen Szenarien ist es sinnvoll, wenn sich die Datenquelle für die Query-Ergebnisse und die Datenquelle für den Upload unterscheiden. Es lassen sich sämtliche Upload-Möglichkeiten mit allen Report-Möglichkeiten kombinieren, auch systemübergreifend!
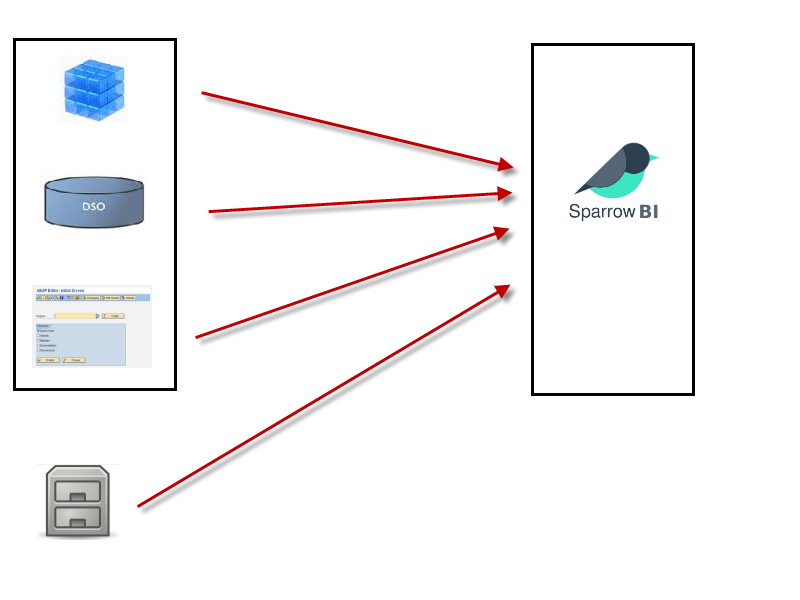
Möglichkeiten des Daten-Uploads zu SparrowBI:
- Archivierung eines Infoproviders Nearline-Storage
- Upload per Report als Kopie der Daten (Full, einmalig manuell)
- Upload per Report als Kopie der Daten (Delta, täglich in Prozesskette)
- Upload von Daten aus Drittsystemen (ohne vorheriges Laden in SAP-BW)
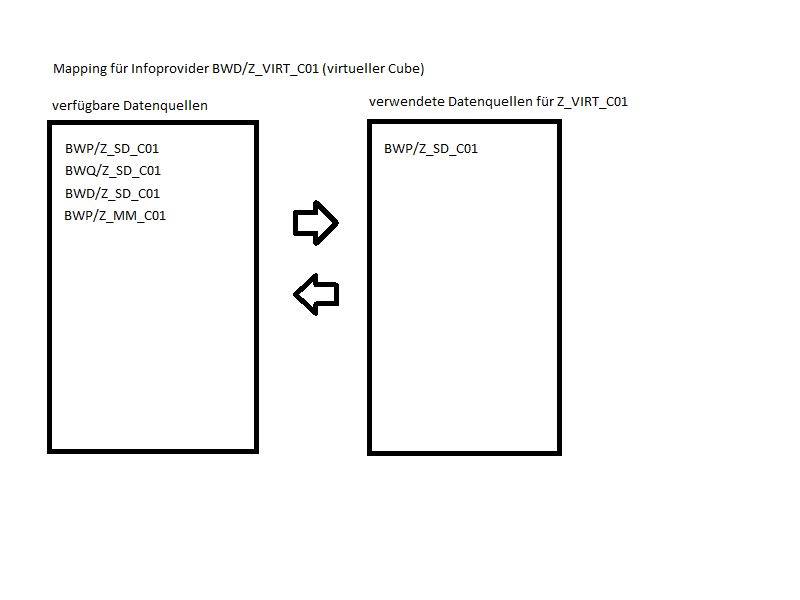
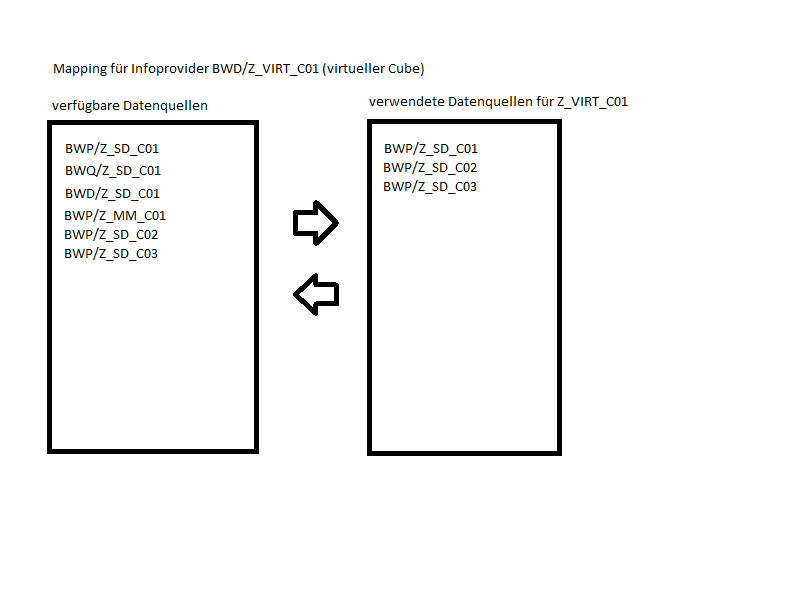
- Upload von Stammdaten aus SAP-BW (Delta, Full) für virtuelle Cubes
Szenario: Reporting von Daten.
Grundsätzlich funktionieren alle Szenarien sowohl mit archivierten Standardcubes als auch mit virtuellen Cubes. Für das Reporting archivierter Cubes erzeugt SAP-BW im Hintergrund einen virtuellen Cube. Welche Technik besser geeignet ist hängt von ihrem Szenario ab:
- Bei virtuelle Cubes sind Navigationsattribute deutlich schneller, da sie von SparrowBI bearbeitet werden.
- Bei virtuelle Cubes müssen Stammdaten in SparrowBI geladen werden, um diesen Vorteil nutzen zu können.
- Nearline-Storage ist sehr einfach zu handhaben, es wird keinerlei Anpassung im Reporting / Multi-Cube benötigt.
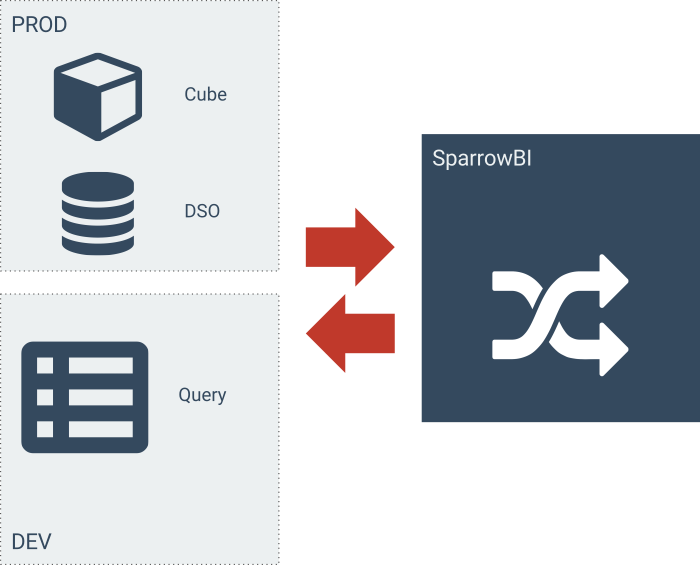
Szenario: Entwickeln und Testen mit aktuellen Daten.
- Im Produktivsystem wird mit Standardinfocubes reported. Ob diese archiviert sind oder nicht spielt keine Rolle.
- Wegen Transportfähigkeit der Cubes muss im DEV/QUAL folglich ebenfalls der Standardinfocubes verwendet werden.
- Im DEV/QUAL wird der Cube geleert und anschliessend vollständig archiviert.
- Dadurch werden Queryanfragen an SparrowBI geroutet.
- SparrowBI wird so konfiguriert, dass Daten aus dem PROD-System reported werden.
- Welche der Uploadtechniken in PROD verwendet wird, spielt dabei keine Rolle.
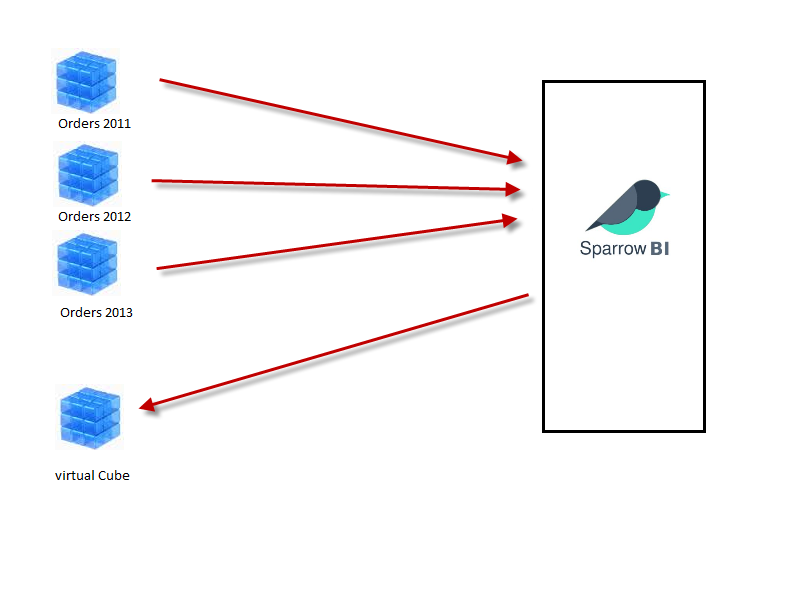
Szenario: Jahrescubes.
In vielen SAP-BW Systemen sieht man identische Cubes, die jedoch unterschiedliche Zeiträume (meist Jahre) enthalten. In solchen Fällen ist ein Multi-Cube definiert, der die Jahres-Cubes zusammenfasst. Im Multi-Provider können die (archivierten) Jahrescubes durch einen virtuellen Cube ersetzen werden. SparrowBI wird entsprechend konfigurien, so dass die Queries wieder das selbe Ergebnis liefern wie vorher.
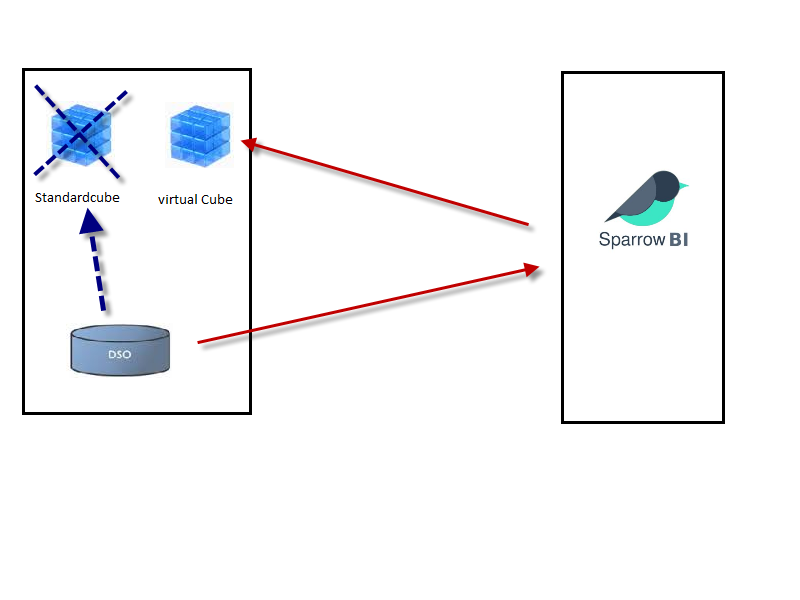
Szenario: DSO-Daten.
Es werden täglich aktuelle Daten geladen. Der Datenfluss enthält ein DSO, vom DSO werden die Daten ohne weitere Logik in einen Cube fortgeschrieben. Es soll die Performance von SparrowBI mit virtuellen Cubes genutzt werden:
- der bisherige Cube wird durch einen virtuellen Cube ersetzt
- die DSO-Daten werden täglich (Prozesskette) per Delta in SparrowBI geladen
- SparrowBI wird so konfiguriert, dass die DSO-Daten im virtuellen Cube reported werden
- Stammdatenupload wird eingeplant um die volle Performance von Navigationsattributen nutzen zu können
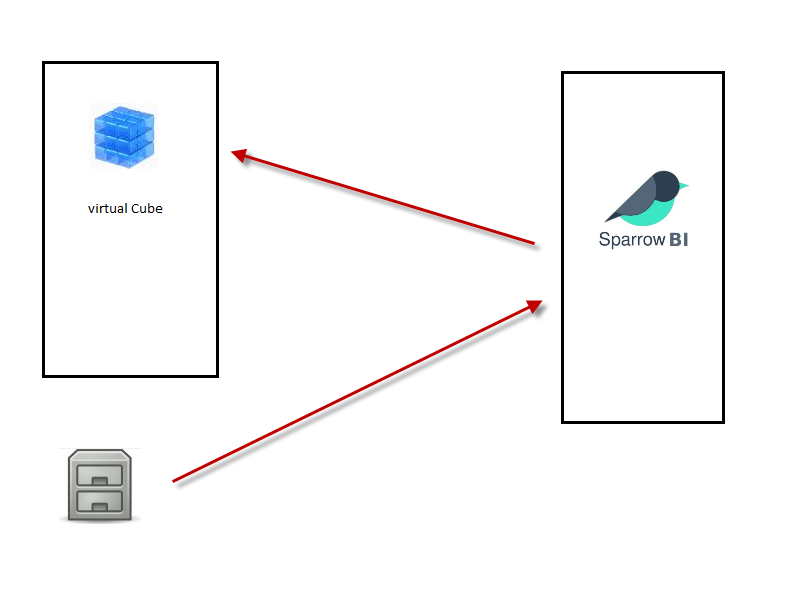
Szenario: Externe Daten.
In diesem Szenario werden die Daten nicht aus einem SAP-BW Infoprovider geladen, sondern direkt aus einem File in SparrowBI geladen. Um die Performance von SparrowBI zu nutzen ist es also nicht notwendig die Daten vorher in SAP-BW zu laden um sie von dort aus in SparrowBI zu laden. In der Konfigurationsoberfläche von SparrowBI wird für den virtuellen Cube als Datenquelle die externen, hochgeladenen Daten eingestellt.